 Log In
Log In 
































Relational databases are the workhorses of data storage; they excel at organizing large amounts of information into a structured format, making it easy to store, retrieve, and manage. Whether you’re managing a company’s customer records, tracking inventory in a store, or building a personal library of movies, a relational database can be your secret weapon.
This comprehensive guide is designed to equip you with the knowledge and tools to build a relational database. We’ll outline the technical aspects of creating tables, defining relationships, and querying data and also explore the theoretical foundations of relational database design.
So, whether you’re a seasoned developer or just starting your journey into the world of data, this guide is here to empower you. Let’s dive in and build a solid foundation for your data management needs.
Relational Database Design Key Takeaways
- A relational database is a structured collection of data organized into tables (or relations) that are connected by defined relationships. This allows for efficient storage, retrieval, and management of data using SQL (Structured Language Query).
- A relational database management system (RDBMS) is software that enables users to create, manage, and interact with relational databases by organizing data into tables with relationships. It ensures data integrity, supports SQL for querying, and enables efficient data storage and retrieval.
- Relational databases are used for storing, organizing, and managing large amounts of structured data, such as customer information, transaction records, and inventory management. They can be used in industries like finance, healthcare, and e-commerce.
What is a Relational Database?
Relational Database Definition and Significance
A relational database is a structured system for storing and organizing data in a way that allows for efficient retrieval and manipulation. It follows the relational model, which emphasizes data organization into tables and the establishment of relationships between those tables.
Here’s why relational databases are crucial for data management:
- Organization: They provide a clear and structured way to store large amounts of data, making it easy to find specific information quickly.
- Data Integrity: The relational model enforces data consistency and reduces redundancy, ensuring the accuracy and reliability of your information.
- Scalability: They can efficiently handle large datasets and accommodate growing data volumes.
- Data Sharing: The structured format allows for easy sharing and manipulation of data across different applications and processes.
The Mathematical Foundations of a Relational Database
The concept of relational databases is rooted in the mathematical theory of relations. A relational database table can be seen as a mathematical relation where each row is a tuple, and the columns represent the attributes of that data.
3 Easy Ways to Start Building For Free
1. Generate an App with AI
2. Use one of our templates
3. Import your own data

Free 14-Day Trial. No Credit Card Required
Understanding this connection helps us grasp the core principles of relational databases:
- Tables: Correspond to mathematical relations, with rows and columns representing tuples and attributes.
- Primary Keys: Uniquely identify each row in a table, similar to how mathematical relations avoid duplicate entries.
- Relationships: Established between tables using foreign keys, which link data points across tables, reflecting the connections between sets in mathematical relations.
By leveraging these mathematical concepts, relational databases ensure data organization, minimize redundancy and enable powerful data manipulation techniques.
Establishing Goals for a Relational Database
Before getting involved in table structures and queries, it’s crucial to establish clear goals for your relational database. Your ideal database should be efficient, adaptable, and perfectly suited to the unique needs of your organization.
Why Setting Goals Matters in Relational Database Design:
- Focus: Clearly defined goals help you identify the data, tables, and relationships that matter most for your organization’s needs.
- Efficiency: A targeted database avoids storing unnecessary information, streamlining storage requirements and retrieval processes.
- Scalability: Goals that consider future growth ensure your database can adapt to accommodate evolving data needs.
How to Define Your Database Goals:
- Identify Data Users: Who will be using this database, and for what purposes? Understanding their needs is key. (e.g., Marketing team, Sales department, Customer support)
- Data Requirements: Identify the specific data fields, attributes, and records your relational database must capture to support accurate reporting and daily operations.
- Desired Functionality: What kind of operations need to be performed on the data? (e.g., Reporting, Data Analysis, Searching)
- Future Considerations: How might your data needs change over time? Will you need to integrate with other systems?
Understanding Data Relationships
The true power of relational databases lies in their ability to establish connections between different tables.
Here’s a breakdown of the different types of data relationships:
- One-to-One (1:1): In this relationship, a single record in one table corresponds to exactly one record in another table. This is less common but can be used in specific scenarios.
- One-to-Many (1:N): This is the most fundamental and widely used relationship. A single record in one table (the “one” side) can be linked to multiple records in another table (the “many” side). This is often achieved through the use of a foreign key, which references the primary key of the “one” side table.
- Many-to-Many (N:N): Here, multiple records in one table can be associated with multiple records in another table. Relational databases cannot directly represent this relationship, but we can create a workaround using an associative table. This associative table has foreign keys referencing both the original tables and establishes the many-to-many connection.
Understanding these relationships is key to designing an efficient and organized database structure. By properly defining relationships, you can:
- Minimize Data Redundancy: Store data only once and avoid duplication across tables.
- Maintain Data Integrity: Ensure consistency and accuracy of information by linking related data points.
- Simplify Data Retrieval: Perform complex queries that span multiple tables to retrieve the information you need.
Relational Database Design Principles (Avoiding Common Pitfalls)
Now that you understand the core concepts of relational databases, let’s explore some best practices for designing them effectively. Following these principles will ensure your database is functional, efficient, manageable, and future-proof.
Relational Database Design Best Practices:
- Normalization: This is a set of techniques to minimize data redundancy and improve data integrity. Normalization involves breaking down tables into smaller, focused tables with well-defined relationships.
- Clear and Consistent Naming: Use descriptive and consistent names for tables, columns, and constraints. This enhances the readability and maintainability of your database.
- Data Types: Choose appropriate data types for each column, such as integers for numbers, dates for time-based data, and text for descriptive information. This ensures data accuracy and efficient storage.
- Constraints: Utilize constraints like primary keys and foreign keys to enforce data integrity and prevent invalid entries.
- Clear Documentation: Document your database design clearly, including table structures, relationships, and the purpose of each field. This is crucial for future maintenance and collaboration.
Common Relational Database Design Pitfalls to Avoid:
- Data Duplication: Avoid storing the same data in multiple places. This can lead to inconsistencies and maintenance headaches.
- Poor Data Naming: Cryptic or inconsistent naming conventions can make the database difficult to understand and navigate.
- Inflexible Design: Don’t anticipate every future need, but design with some level of flexibility to accommodate potential growth and changes.
- Security Oversights: Failing to apply proper access controls, permissions, and data protections can expose sensitive information within your relational database.
- Lack of Testing: Thoroughly test your database design and queries before deploying them to real-world use cases.
The Role of SQL in Database Creation in Relational Databases
SQL (Structured Query Language) is the cornerstone of interacting with relational databases. It’s a powerful and standardized language that allows you to create, manipulate, and retrieve data from your database.
Here’s a glimpse into how SQL empowers you to manage your relational database:
- Database Creation: SQL commands like CREATE TABLE enable you to define the structure of your tables, specifying columns, data types, and constraints.
- Data Manipulation: SQL provides a rich set of commands for inserting, updating, and deleting data within your tables. (e.g., INSERT, UPDATE, DELETE)
- Data Retrieval: The SELECT statement is the heart of data retrieval in SQL. You can use it to extract specific data points or entire rows based on various criteria and filter conditions.
- Data Relationships: SQL allows you to establish relationships between tables using foreign keys. This is often achieved through the FOREIGN KEY constraint within the CREATE TABLE statement.
How to Build a Relational Database
Now that we’ve explored the fundamental concepts and design principles, let’s build a simple relational database using SQL.
Step 1: Define Your Database Purpose and Data Needs
Here, you’ll identify the purpose of your database and the specific data points you want to manage.
- What kind of information will you be storing? (e.g., Customer information, Product inventory, Library of books)
- Who will be using this database, and how? (e.g., Sales team, Marketing department, Personal reference)
By answering these questions, you can determine the tables you need and the attributes (columns) within those tables.
Step 2: Entity-Relationship Model (ERM) Creation (Optional)
Creating an Entity-Relationship Model (ERM) can be a helpful visualization tool, especially for complex data structures. An ERM is a diagram that represents the entities (tables) in your database and the relationships between them.
Step 3: Building Tables with SQL
Once you have a clear understanding of your data, it’s time to translate that knowledge into SQL commands to create the tables in your database. Here’s a breakdown of the process:
- Use the CREATE TABLE statement: This command defines the structure of your table, specifying its name and the columns it will contain.
- Define Columns: For each column, specify its name, data type (e.g., text, integer, date), and any constraints like primary key or foreign key.
Relational Database Table Example (SQL):
SQL
CREATE TABLE Customers (
customer_id INT PRIMARY KEY AUTO_INCREMENT,
first_name VARCHAR(50) NOT NULL,
last_name VARCHAR(50) NOT NULL,
email VARCHAR(100) UNIQUE
);
This code creates a table named “Customers” with four columns:
- customer_id: An auto-incrementing integer that uniquely identifies each customer (primary key).
- first_name: Customer’s first name (text, not null).
- last_name: Customer’s last name (text, not null).
- email: Customer’s email address (text, unique).
Step 4: Establishing Relationships with Foreign Keys
Now that you have your tables defined, it’s time to establish relationships between them if necessary. Foreign keys are used to link data points across tables, enforcing referential integrity and preventing inconsistencies.
Example: Creating Table Relationships with Foreign Keys
SQL
CREATE TABLE Orders (
order_id INT PRIMARY KEY AUTO_INCREMENT,
customer_id INT NOT NULL,
order_date DATE,
FOREIGN KEY (customer_id) REFERENCES Customers(customer_id)
);
Here, the Orders table is created with a foreign key customer_id that references the primary key of the Customers table. This ensures that each order has a valid customer associated with it.
Step 5: Populating Your Database with Data
With your tables in place, you can start inserting data using the INSERT statement in SQL.
Step 6: Querying Your Database
Finally, the power of your relational database lies in its ability to retrieve specific data. SQL’s SELECT statement allows you to query your database based on various criteria, filtering and sorting data to answer your questions and generate reports.
Identifying Data Requirements:
It’s crucial to identify your data requirements in great detail. This initial phase allows for a structured and efficient database that perfectly aligns with your application or business needs.
Here, we’ll explore a step-by-step process to identify your data requirements:
1. Define the Purpose and Scope:
- What problem are you trying to solve, or what information do you need to manage? (e.g., Tracking customer orders for an e-commerce store, Managing employee information for a company)
- Who will be using this data, and for what purposes? (e.g., Sales team, Marketing department, Human Resources)
2. Identify Entities:
- Entities are the core building blocks of your data model. They represent the real-world objects or concepts you want to store information about. Think of them as the “things” in your data universe. (e.g., In an e-commerce store, entities could be Customers, Products, or Orders)
3. Define Attributes:
- Once you have your entities identified, it’s time to determine the specific characteristics or details you want to capture for each one. These characteristics become the attributes (columns) of your database tables. Ask yourself: What information do you need to know about each entity?
4. Identify Relationships:
- In the real world, entities rarely exist in isolation. They often have connections with each other. Your data model needs to reflect these relationships to accurately represent the information structure. Analyze how your entities interact and identify the nature of those relationships. A Product can be included in many Orders, and an Order can contain multiple Products (Many-to-Many relationship – typically requiring an associative table).)
Tips for Effective Data Requirement Identification:
- Involve Stakeholders: Get input from different departments or users who will be working with the data.
- Start Simple, Iterate Often: Begin with a core set of entities and attributes. As your understanding evolves, refine and expand your data model.
- Document Everything: Clearly document your data requirements, including entity definitions, attribute details, and relationship descriptions.
Defining a Relational Database Schema:
Knack’s no-code platform offers a user-friendly interface for building database schemas without writing code. Here’s a step-by-step guide on designing your schema using Knack:
1. Accessing the Knack Builder:
- Log in to your Knack account or create a free trial.
- Click on “New App” to initiate the app-building process.
2. Creating Tables:
- Knack uses tables to represent your data entities.
- Click on “Add Table” to create a new table.
- Give your table a descriptive name that reflects the entity it represents (e.g., Customers, Products, Orders).
3. Defining Fields (Columns):
- Each table will contain fields that represent the attributes of your entity.
- Click on “Add Field” to define a new field.
- Choose the appropriate data type for your field based on the information you want to store (e.g., Text for names, Number for prices, Date for order dates).
- Give your field a clear and concise name that reflects its purpose (e.g., first_name, product_price, order_date).
4. Setting Up Relationships:
- Knack allows you to establish relationships between tables using connected fields.
- To create a relationship, navigate to the table containing the “one” side of the relationship (e.g., the Customers table).
- Click on “Add Connected Field“.
- Select the table representing the “many” side of the relationship (e.g., Orders table). This creates a foreign key connection.
- Choose the field in the “one” table that will be used for linking (e.g., customer_id in the Customers table).
Optimizing Performance and Scalability of a Relational Database:
A well-designed relational database is a powerful tool, but like any tool, it needs proper maintenance. Here are best practices to keep your database running smoothly as your data volume and user base grow.
Enhancing Database Performance:
- Indexing Key Fields: Indexes act like reference catalogs in a library, allowing for faster data retrieval. Identify frequently used columns in your queries and create indexes on those fields. This significantly improves query execution speed.
- Optimize Queries: Write efficient SQL queries that avoid unnecessary operations or filtering conditions. Analyze slow queries and identify areas for improvement.
- Hardware Optimization: Ensure your database server has sufficient resources (CPU, RAM) to handle the workload. Consider upgrading hardware if performance bottlenecks arise.
Ensuring Scalability:
- Denormalization (Strategic): In some cases, denormalization can improve read performance by duplicating certain data points across tables.
- Archiving Old Data: Don’t overload your database with inactive or historical data. Regularly archive to keep your active tables lean and efficient.
- Horizontal Scaling (Sharding): For massive datasets, consider horizontal scaling. This involves distributing data across multiple servers.
Planning for the Future of Your Relational Database:
- Choose the Right Database Engine: Select a database engine that fits your specific needs and anticipated data growth. Consider factors like performance, scalability, and available features.
- Design for Growth: While building your schema, factor in potential future needs. Leave room for adding new tables or fields without compromising the overall structure.
- Regular Monitoring: Proactively monitor your database performance and identify potential bottlenecks before they become critical issues. Regularly analyze query execution times, storage usage, and user activity.
Relational Database Testing and Iteration:
Building a relational database is an iterative process. Just like any software development project, thorough testing and continuous improvement can create a robust and user-friendly system.
Why Testing Matters
- Data Integrity: Testing helps identify data inconsistencies, invalid entries, and potential breaches of referential integrity. This ensures your data remains accurate and reliable.
- Functionality: Verify that your database functions as intended. Test different queries, data manipulation operations, and user workflows to identify any bugs or shortcomings.
- Performance: Evaluate the performance of your database under various load conditions. This helps pinpoint areas for optimization and ensures the system can handle real-world usage.
Testing Strategies:
- Unit Testing: Test individual components of your database schema, such as table structures and queries, in isolation. This helps isolate issues early in the development process.
- Integration Testing: Test how different parts of your database interact with each other, ensuring smooth data flow and consistency across tables.
- User Acceptance Testing (UAT): Involve your end-users in testing the database. Their feedback is invaluable for identifying usability issues and ensuring the system meets their needs effectively.
Choosing and Setting Up Primary Fields in a Relational Database
The primary key is a fundamental concept in relational databases. It acts as a unique identifier for each row in a table, ensuring data integrity and efficient data retrieval. Choosing the right primary key is crucial for establishing a solid foundation for your database.
Criteria for Selecting Primary Keys:
- Uniqueness: The primary key value must be unique for every row in the table. No two rows can have the same primary key value.
- Not Null: The primary key field should not allow null values. Every row must have a defined primary key value.
- Simplicity and Efficiency: Ideally, the primary key should be concise and allow for efficient retrieval of data.
Common Primary Key Types:
- Auto-Incrementing Integers: This is a popular choice for primary keys. The database automatically generates a unique integer for each new row, ensuring uniqueness and simplicity. (e.g., customer_id in a Customers table)
- Unique Natural Keys: In some cases, a natural attribute of an entity can serve as a unique identifier. For example, a Social Security number (assuming appropriate privacy considerations) could be a primary key in an Employee table, provided duplicates are strictly controlled.
- Composite Keys: When no single attribute is inherently unique, a combination of two or more attributes can be used as a composite primary key. This is often used for tables linking multiple entities. (e.g., A combination of order_id and product_id in an Order_Details table linking Orders and Products tables)
Problem-Solving Within Database Construction
Relational databases require regular maintenance, so you may need to address issues in your design as your data needs evolve. Here’s how:
- Data Redundancy: Avoid storing the same data in multiple places. Normalize your tables and use foreign keys to create relationships.
- Performance Issues: Optimize queries, create indexes on frequently used fields, and consider hardware upgrades if needed.
- Scalability Challenges: Plan for growth! Denormalize strategically, archive old data, and explore horizontal scaling for massive datasets.
- Testing Oversights: Thoroughly test your database design! Involve users, identify bottlenecks, and iterate based on feedback.
Building a Relational Database with Knack
This comprehensive guide has equipped you with the knowledge and best practices to navigate the world of relational databases. You’ve learned how to:
- Define your data requirements and identify key entities and relationships.
- Design a well-structured schema using Knack’s no-code builder or traditional SQL.
- Optimize your database for performance and scalability to handle growing needs.
- Implement a rigorous testing and iteration process to ensure data integrity and user satisfaction.
Building a database with Knack is far simpler than doing this from scratch. Following our “working with records” guide will give you everything you need to know about building your table, fields, and records to start building custom software applications.
Knack uses tables and fields to define your data. Tables are used to separate your data into common groups. You can think of a table like a spreadsheet or a database table. Fields are used to define specific attributes of a table. Think of a field as a spreadsheet column. You’ll want to add a field for each attribute you want to store for a given table.
Once you’ve signed up for Knack, you can access your tables by clicking on the “Data” button in the top left of the Builder (inside your new project):
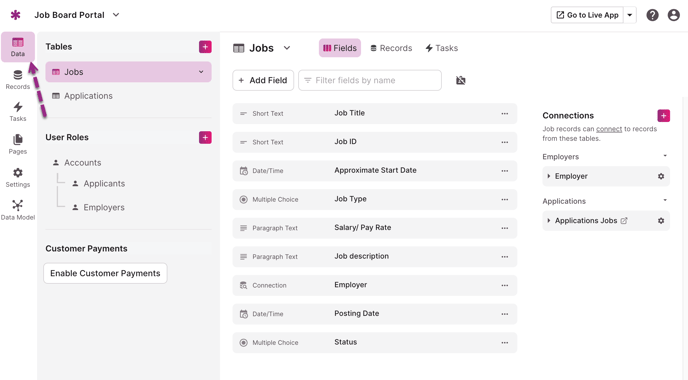
From here, you can start defining your database records, tables, fields, and overall schema to build your application. This makes the process of building relational databases much easier.
Start building your relational database for free today with Knack!
Relational Database FAQs
What is a relational database, and why is it important for businesses?
A relational database is a type of database that organizes data into tables with rows and columns and establishes relationships between these tables based on common fields. It’s important for businesses because it provides a structured and efficient way to store, manage, and retrieve data.
How does Knack facilitate the building of relational databases?
Knack provides a user-friendly platform that allows users to build custom relational databases without writing any code. With its intuitive drag-and-drop interface and customizable templates, Knack empowers users to design database schemas, define relationships between tables, and create forms and views for data entry and retrieval, all without the need for technical expertise.
What are the key components of a relational database built with Knack?
Key components of a relational database built with Knack include tables, which store data in rows and columns; fields, which represent the attributes of the data stored in each table; relationships, which define connections between tables based on common fields; forms, which allow users to enter and edit data; and views, which display data in different formats for analysis and reporting.
Can I import existing data into a relational database built with Knack?
Yes. You can import existing data into a Knack relational database from spreadsheets, CSV files, and other data sources. Knack’s field-mapping tools help ensure your data is organized correctly as it’s added to your tables.
How scalable are relational databases built with Knack?
Relational databases built with Knack are highly scalable and can accommodate growing data volumes and user bases. Knack offers flexible pricing plans that allow users to scale their databases and applications as needed, with options for additional storage, users, and features.







