 Log In
Log In 
































Database schemas play a critical role in the design and organization of data as they provide the blueprint for how it is structured, stored, and accessed. While not all historical database schemas are still useful today, it’s important to have a general understanding of the different schemas out in the world so you can assess how others have tackled similar problems in the past.
By understanding the foundations of database schemas and the different types of models available, you can gain valuable insights into the database management field, and the best designs for online databases. We will also explore some tips on how to choose the correct database schema for your business. But first things first, what is a database schema?
What is a Database Schema?
A database schema is a collection of metadata that represents the structure and organization of a database. It includes definitions of:
- Tables
- Columns
- Constraints
- Relationships
Together these elements define how data is stored and related. The schema is, in short terms, the backbone of a database management system or DBMS, which provides a structured way of storing and retrieving data. It’s a visual heuristic that can help teams plan out the best possible data storage option for their needs and begin to think about how these design choices will interact with the real world.
The importance of well-designed schemas cannot be overstated, as they lay the groundwork for effective data management, improved data integrity, and efficient data retrieval. After all, the schema is the structure responsible for determining the rules governing the data in these systems.
13 Database Schema Models You Should Know
There are several different types of database schema models, which are logical framework that defines the structure and organization of data in a database. So let’s take an in-depth look at these models and their top advantages and disadvantages.
1) The Hierarchical Model
The hierarchical model organizes data in a tree-like structure with parent-child relationships, resembling an upside-down tree or the roots of a tree This model holds a strict one-to-many relationship between records. Because of this, it is most useful for file systems where data is cleanly nested.
These models are simple to understand and efficient for one-to-many relationships. However, you could struggle with many-to-many relationships and it has a significant lack of flexibility.
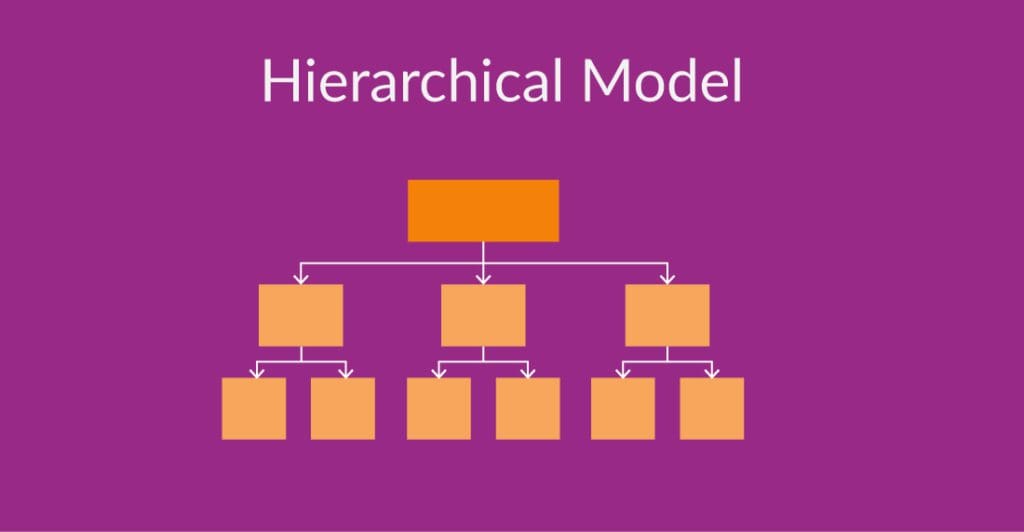
For example: Imagine a hierarchical model used to represent a company’s organizational structure. Each employee would be a child record of their respective manager, forming a hierarchical chain of command. However, if an employee were to have multiple managers or move to a different department, it would become more difficult to manage. Situations like these are not ideal for hierarchical models as the interconnection between records begins to interfere with the intent of the system.
2) The Network Model
The network model builds on the hierarchical model’s foundation by introducing the notion of sets, which can have multiple parent and child records.They are ideal for real world applications like airline reservation systems or scientific databases where the associations between records matters to end users for.
This flexibility allows for better modeling of many-to-many relationships. However, their complexity can make them challenging to implement and maintain.
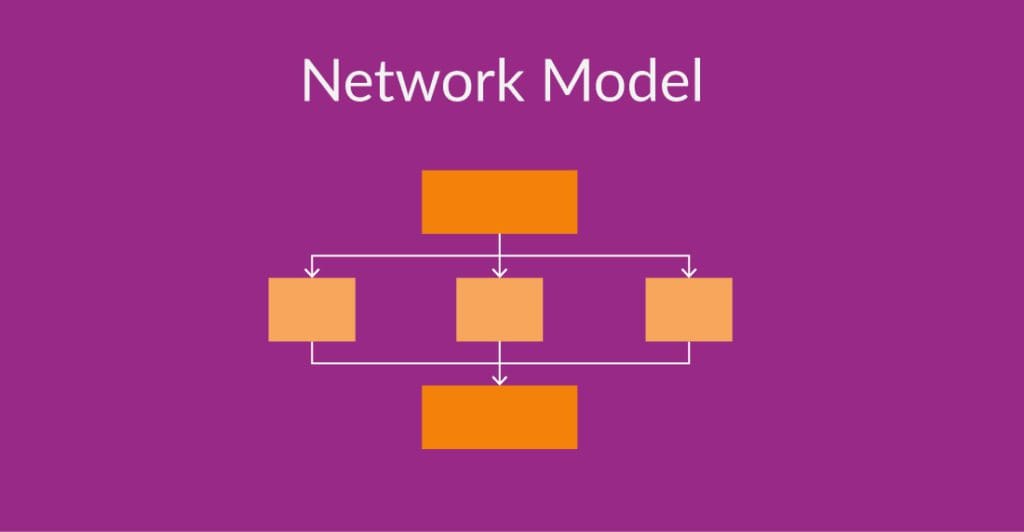
For example: In a company organizational structure, the network model would allow an employee to have multiple managers or belong to multiple departments, providing a more accurate representation of real-world scenarios.
3) The Object-Oriented Database Model
The object-oriented database model allows for the storage and retrieval of complex objects directly in the database. These models blur the line between application code and database storage, enabling a more efficient and natural representation of real-world objects.

For example: In the context of a social media platform, an object-oriented database model could store user profiles as objects with attributes such as name, age, and interests, making it easier to develop applications that interact with the database. Likewise this would be an ideal way to think about either deals or individual customers or even sets of these data points within a custom CRM.
4) The Object-Relational Model
The object-relational model extends the relational model to include user-defined data types, methods bringing object-oriented concepts into a relational database environment. This model enables more flexible data modeling while retaining the robustness and ease of use of relational databases.
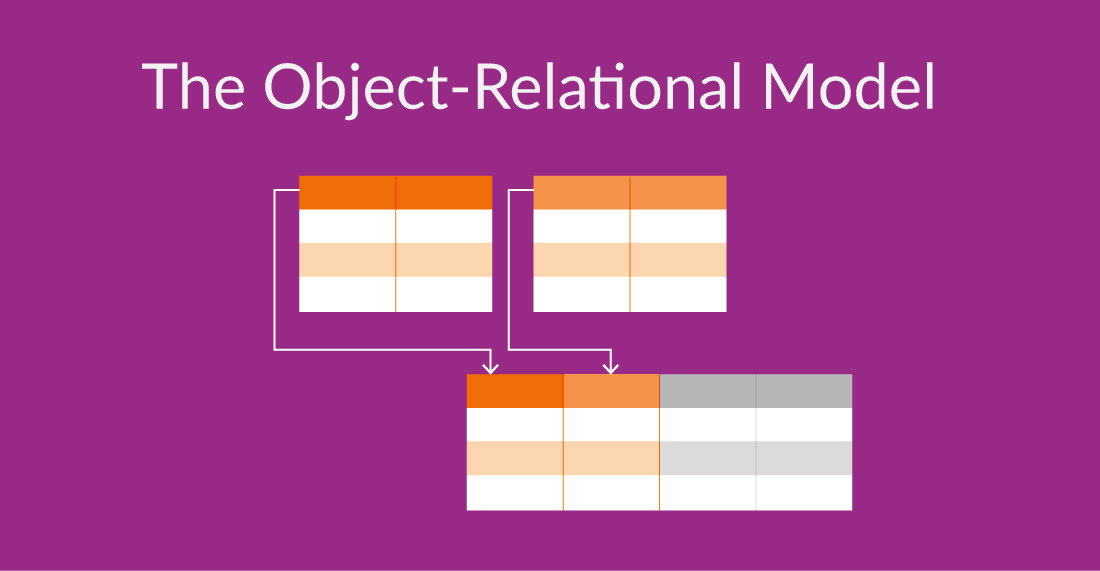
For example: For instance, in a banking system, the object-relational model could be used to represent customers as objects with attributes like name, address, and account balance and define methods to perform operations such as depositing or withdrawing money from the account. If you think about how you manage your own customers’ interactions with your company this could be another great model to think of when building a custom CRM database.
5) The Entity-Relationship Model
The entity-relationship (ER) model is a widely used conceptual modeling technique that represents real-world entities and their relationships. It provides a graphical representation of data, which makes it easier to identify the relationships between the data, ensuring a well-organized and efficient database structure.
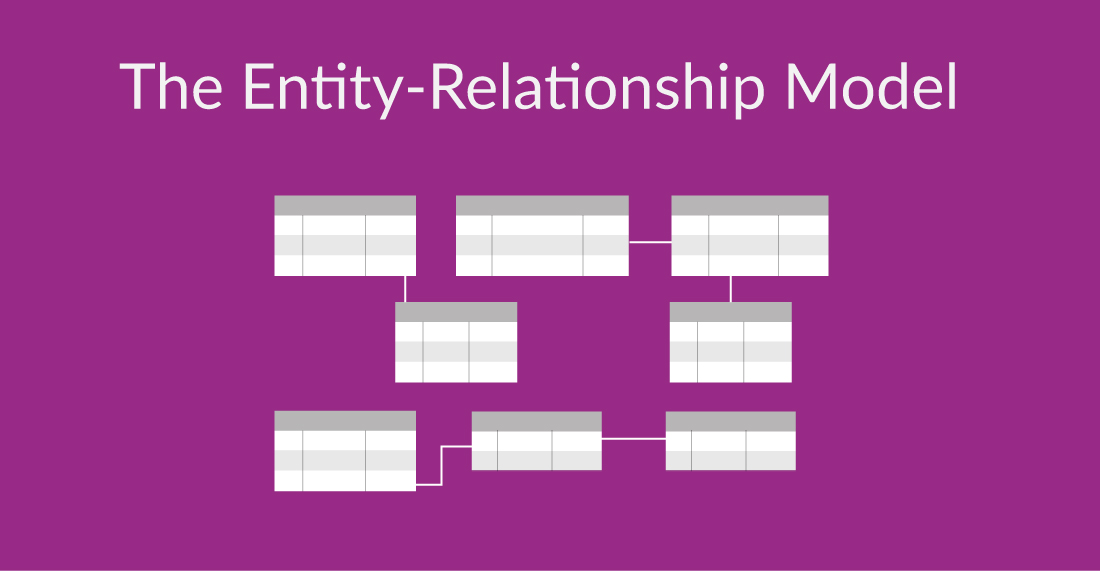
For example: You can design an e-commerce website, with entities such as customers, products, and their orders, along with their attributes and relationships. All in one easy to view graphical representation of online transactions for your business.
6) The NoSQL Database Models
NoSQL databases employ various data models that differ significantly from traditional relational models. Two popular NoSQL database models include:
- The inverted file model, which stores an index of terms and the documents in which they occur. This allows for efficient searching and retrieval, making it an ideal choice for scenarios where rapid and accurate searching is crucial.
- The flat model, which stores data in a flat, tabular structure without any predefined relationships between tables. Each record in the flat model is independent and self-contained.

Understanding the different models and their characteristics is essential for designing efficient and scalable databases. Whether banking financing or creating a search engine, NoSQL databases might be the fit for you. The only downside is that the lack of structure can turn flexibility into a nonsensical mess.
7) The Multidimensional Model
The multidimensional model has the ability to handle complex queries efficiently. In this model, data is organized into dimensions, which represent various attributes like product, time, geography and demographics; and measures, which quantify the data and provide numerical values for analysis.
To provide a visual representation of the data, the multidimensional model also utilizes a cube-like structure called an OLAP (Online Analytical Processing) cube, allowing users to interact with the data intuitively.

These systems are particularly valuable in decision-making processes, which is why they are commonly used in data warehousing and business intelligence systems. There are tons of benefits to multidimensional. They can:
- Provide valuable insights into the performance of a business
- Identify trends and patterns
- Perform calculations and aggregations across multiple dimensions
- enable you to select a specific subset of databases on certain criteria and analyze data from multiple dimensions simultaneously.
This model empowers businesses to make informed decisions and optimize their operations. With its ability to handle complex queries efficiently and provide a visual representation through OLAP cubes, the multidimensional model enables businesses to gain valuable insights and make data-driven decisions.
8) The Semi-Structured Model
The semi-structured model is designed to handle data with varying structures, making it suitable for scenarios where data may not conform to a rigid schema. In this model data is organized using flexible formats such as XML or JSON which allows for easy integration and interoperability.
For example: On an e-commerce website, the semistructured model can be used to store product information like name, price, description, and customer reviews, allowing for additional attributes to be added or modified as needed without requiring a complete overhaul of the database structure. This kind of system would be ideal for large ecommerce marketplaces where site operators may not have full control of all product types and categories that will eventually get sold.
One of the key advantages of the semi-structured model is its ability to handle data that may have different structures across different instances. This is particularly useful in scenarios where data is collected from various sources, such as social media platforms or IoT devices.
However, unlike structured databases, where data is organized in predefined tables and columns, the semi-structured model lacks a formal structure. This makes it difficult to perform complex queries or extract specific information from the data.
9) The Context Model
Complex systems often involve intricate interactions between data entities, making it challenging to comprehend the overall picture. This is where the context model shines, as it represents the interconnections between different data elements.
This model also allows organizations to gain insights into the impact of changes or disruptions in one part of the system on other interconnected parts. By visualizing these relationships, organizations can proactively identify potential bottlenecks or risks and take appropriate measures to mitigate them.

For example: Let’s consider a scenario where a supplier experiences a delay in delivering raw materials to a manufacturer. The context model would highlight the dependencies between the supplier and manufacturer and the subsequent impact on the customers.
10) The Associative Model
The associative model focuses on representing relationships between data entities without strictly enforcing a predefined schema allowing for the creation of associative arrays or key-value pairs where data elements are related through common attributes.
This model allows for efficient traversal and discovery of connections between data elements, and a more dynamic representation of data, where relationships can evolve and adapt over time.
For example: In a social network application, users can be represented as nodes, and their relationships (such as friendships or followers) can be represented as edges. By leveraging the associative model, it becomes easier to analyze and extract meaningful insights from the network structure.
The associative model offers advantages in terms of data exploration, query efficiency, and adaptability to evolving data structures. Whether in social networks, recommendation systems, or fraud detection, the associative model proves to be a valuable tool for analyzing and understanding complex data relationships.
11) The Star Schema Model
The star schema model is a widely used dimensional model in data warehousing. It organizes data into a central fact table surrounded by dimension tables. The central fact table contains the measures, while the dimension tables contain the attributes related to the measures.
This model resembles a star shape when visually represented, with the fact table at the center and the dimension tables radiating outwards. The star schema model is designed to optimize query performance and simplify data analysis for decision support systems and reporting applications.
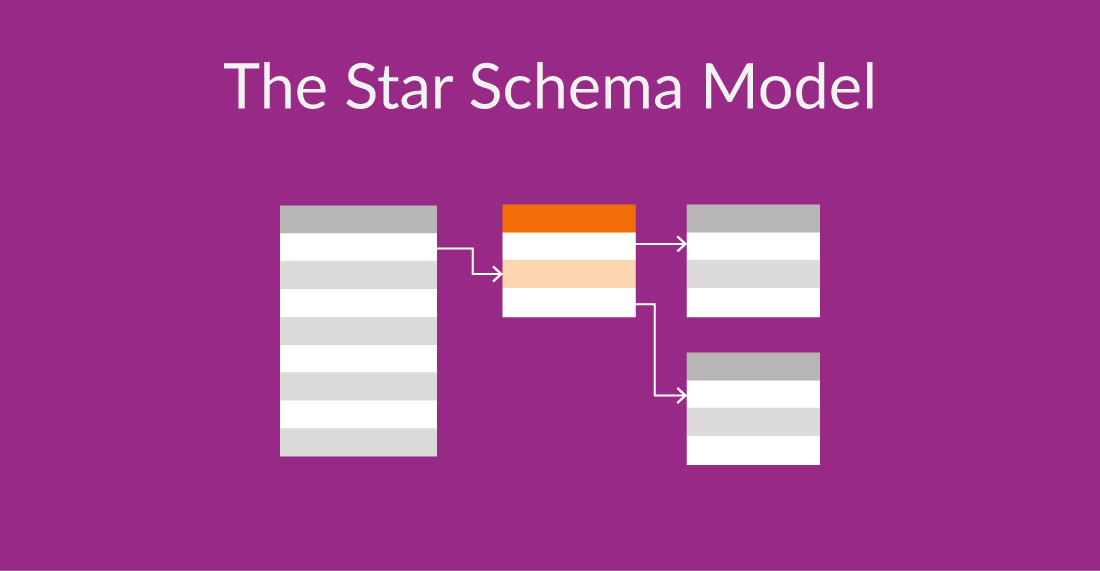
Moreover it provides fast data retrieval and efficient aggregation of data. This means that complex calculations, such as summing up sales figures or calculating average customer satisfaction scores, can be performed quickly and easily.
However, since the model is designed to optimize query performance, it may not be the best choice for situations where the data relationships are intricate and constantly changing. In such cases, a more flexible data model, such as a snowflake schema, may be more appropriate.
12) The Snowflake Schema
The snowflake schema is an extension of the star schema, where dimension tables are further divided into sub dimension tables, creating a more complex structure resembling a snowflake shape.
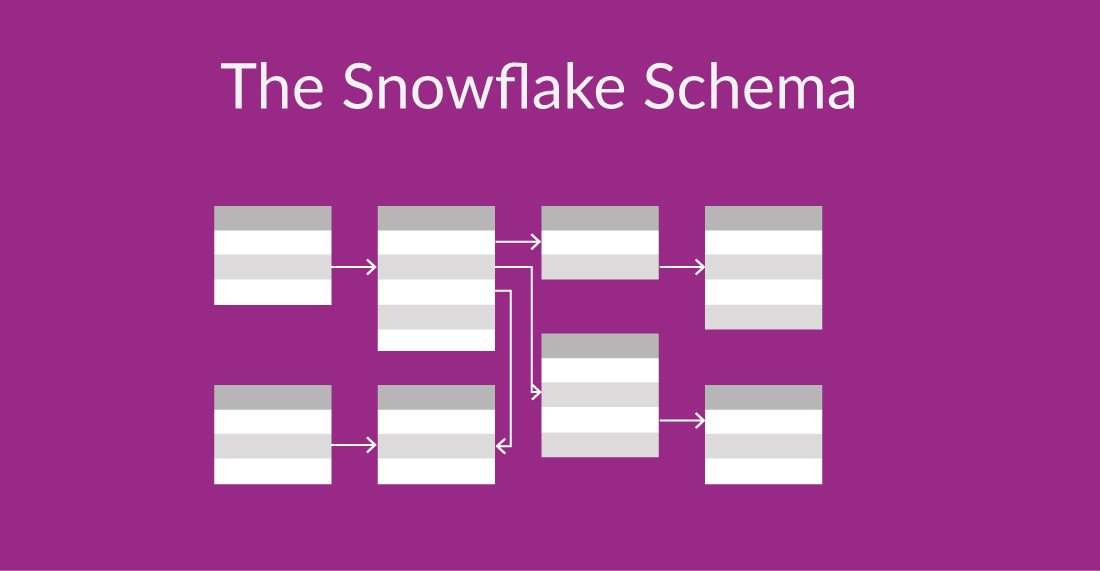
One advantage of the snowflake schema is that it allows for better data integrity. By breaking down dimension tables into sub dimension tables, each sub dimension can have its own set of constraints and validations. This reduces data redundancy and improves data integrity, making this model useful when dealing with large databases. However, the snowflake schema can result in more complex query operations due to the additional tables and relationships, making it more time-consuming and resource-intensive compared to querying data from a star schema.
13) The Fact Constellation Schema
The constellation schema, also known as the galaxy schema, is a hybrid model that combines multiple star schemas. In this model, each fact table is associated with its own set of dimension tables, but they can share some common dimensions allowing for more diverse and flexible analysis across different fact tables.

For example: With the fact constellation schema,a retail company can have separate fact tables for sales by product category and sales by region. Both fact tables can share common dimension tables such as product, customer, and date; enabling the company to analyze sales data by product category, by region, or by a combination of both.
This schema also has the ability to handle many-to-many relationships between dimensions, allowing for more flexible analysis. Furthermore, you can easily add new fact tables without modifying the existing schema. Despite its advantages, the constellation schema can come with increased complexity that could affect query optimization, especially when dealing with large data volumes.
Factors to Consider When Choosing Your Database Schema
When it comes to selecting a database schema, various factors must be considered to ensure optimal performance and efficiency. You must consider:
- The volume and velocity of your data which will determine the scalability and responsiveness of your database schema
- The structure and complexity of your data which will define the flexibility you need.
- The frequency in which new data will be added, modified, or deleted.
- The type of industry you operate in as it determines the type of data you store.
- The desired outcomes of data analysis should also inform your decision.
- The level of data integration and interoperability required by your business.
- The scalability and performance requirements of your business.
- The level of data integration and interoperability required by your business should also be taken into account.
Considering these 8 factors will help you determine the complexity, flexibility, and scalability of the database schema you need for your business. And choosing the right one can have a huge impact on your business.
The 4 Main Theoretical Foundations of Database Schemas
There are a ton of theoretical foundations that have laid the groundwork for database schemas over the years. So let’s get into the main four foundations so we can better understand how schemas work.
1) The Concept of Normalization
Normalization is a process that helps eliminate data redundancy and ensure data integrity by organizing data into logical and efficient structures. By adhering to normalization principles, database designers can minimize data anomalies, which can lead to inconsistencies and inaccuracies in the data.
2) The Entity-relationship (ER) Model
The ER model is a visual representation of the relationships between entities in a database. It helps database designers identify entities, attributes, and relationships and translate them into a schema. This provides a high-level view of the database structure, making it easier to understand and communicate the database design.
3) The Set Theory
Database schemas also draw inspiration from set theory, which is a branch of mathematical logic that provides the foundation for defining relationships between entities in a database. By applying set theory principles, database designers can accurately represent complex relationships and ensure data consistency.
4) The Concept of Data Modeling
Data modeling is the process of creating a conceptual representation of the data requirements for a database. It involves identifying entities, attributes, and relationships and translating them into a schema which helps bridge the gap between the real-world domain and the database system, enabling effective data management and manipulation.
By understanding and applying these foundations, database designers can create robust and efficient schemas that facilitate effective data management and retrieval. So now that you know these foundations, you also need to know the types of database schemas available in the market so you can make an informed decision.
4 Common Modern Approaches to Database Schemas
Traditionally, database schemas have been synonymous with the rigid structure of relational databases. However, with the advent of new technologies and the explosion of data sources, alternative approaches to schemas have emerged. These alternatives have lent flexibility to developers, and especially in the case of no-code databases divorced schema design from the end user’s experience. Here are the main four modern approaches to database schemas:
1) NoSQL Databases
NoSQL offers flexibility and scalability by diverging from the rigid structure of traditional schemas. In NoSQL data is stored in a more fluid and flexible manner, allowing for rapid iteration and accommodating ever-changing data requirements. NoSQL databases come in various forms, such as:
- Document-oriented, like MongoDB, which stores data in flexible JSON-like documents, allowing for easy handling.
- Key-value, which are optimized for high-speed data retrieval and are commonly used in caching and session management.
- And graph databases.
2) Schema-on-read
Another modern approach to database schemas is found in data warehousing and big data environments. In these scenarios, schemas are designed to handle massive volumes of data with diverse structures and formats. Instead of conforming to a predefined schema, data warehousing and big data schemas embrace schema-on-read.
Schema-on-read allows users to structure and interpret the data at the time of analysis, rather than imposing a rigid structure upfront. This approach is particularly useful when dealing with unstructured or semi-structured data, such as social media feeds, log files, or sensor data. As this data shows no signs of slowing down in the coming years, schema-on-read’s database systems are sure to see significant use.
3) Cloud-based and online databases
Cloud-based and online databases have also revolutionized the way database schemas are implemented. With the increasing popularity of cloud computing and the Software-as-a-Service (SaaS) model, organizations can now leverage scalable, on-demand database solutions that eliminate the need for upfront infrastructure investment.
Cloud databases, such as Amazon Web Services’ Amazon Aurora or Google Cloud’s Cloud Spanner, provide managed database services that handle the underlying infrastructure, including scalability, availability, and backups.
4) Platform-as-a-Service Systems
Furthermore, the rise of Platform-as-a-Service (PaaS) offerings provides developers with a fully managed database platform that abstracts away the complexities of database administration. With PaaS databases, developers can focus on building applications without worrying about infrastructure management, allowing for faster development cycles and reduced time-to-market. The end user experience also makes integrations, reporting, and usability across the team much easier creating easy online databases usable by the entire team.
No-code solutions in particular have revolutionized how teams work and process data. Even the most technically advanced users find that PaaS solutions help them create web apps they could build, but don’t necessarily want to invest the time on. For example their are hundreds of universities and corporate IT teams that leverage our equipment inventory database template to quickly track tool usage without complicating other internal systems. Often even companies with significant ERP infrastructure benefit from rapid deployment of custom inventory management solutions geared towards new business lines, or new supplier routes. Finally almost any team, organization, or club can easily build many different types of web portals that help them manage internal activities. As technology continues to evolve organizations will find more and more accessible no-code approaches to solve issues and choose the one that best fits their data requirements and business needs. Now that we have gotten into the foundations of database schemas, types, and modern focus areas, it’s time to discuss how to choose the right database schema for your business.
The Influence of the Technology Stack on Schema Selection
Your technology stack will also influence your choice of database schema. If you are already invested in a particular database technology or programming language, it may be advantageous to leverage a schema that aligns with your existing infrastructure. This compatibility ensures seamless integration and minimizes implementation complexities. Moreover, the scalability and performance characteristics of your chosen technology stack should always be a huge consideration. Evaluating the performance benchmarks and limitations of your technology stack can help guide your schema selection process. In most cases the throughput you need will give you a clear answer, or purely best practices in your space. When it comes to merging best practices with team ability this is often where friction and challenges arise in projects.
Regardless of what your team is capable of the availability of skilled resources and support for your chosen technology stack should also be taken into account. If there is a strong community and abundant resources available for a particular project, it should be easier to find developers and administrators with the necessary expertise to manage and optimize your chosen schema. This has particular importance in no-code environments where dependency on a platform provider will determine your long term success.
The Future Database Schemas
The rapidly evolving landscape of data management continues to push the boundaries of traditional database schemas. Looking ahead, several trends are poised to shape the future of schema design.
One trend is the increasing adoption of graph databases. Graph databases are designed to represent relationships between data points, making them particularly useful for applications that require complex querying and analysis. As companies strive to gain deeper insights from interconnected data, the demand for graph database schemas is expected to grow.
Another emerging trend is the proliferation of containerization and microservices architectures. In these environments, schemas need to be designed with scalability, agility, and interoperability in mind. Schema evolution becomes a critical consideration as databases are scaled horizontally and new services are added to the architecture.
In addition, the use of microservices enables organizations to develop and deploy new features independently without impacting the entire system. This decoupling of services necessitates flexible and adaptable database schemas that can accommodate frequent changes and updates. This trend, coupled with the blossoming of no-code technologies has decoupled technical development from programing experts, and put the power into the hands of users. It’s likely as this trend continues companies will split into specialized large scale corporations and hyper efficient teams focused on sales and operations with no-code backbones supporting their performance.
The exploration of database schemas is an essential aspect of navigating the complex world of data management. By understanding modern approaches, considering relevant factors, and anticipating future trends, businesses can make informed decisions that drive data-driven success. If you want to easily get started building an interactive online database for your team or company, sign up for a free trial of Knack today. Our no-code platform is specifically geared towards the integrations, interoperability, scaling, and security needs of modern organizations. With a huge library of applications and thriving support community organizations of all sizes across the world have found success easily managing data.







